転写とRNAプロセッシングによって作製されたmRNAの遺伝情報は、遺伝暗号にしたがってタンパク質のアミノ酸配列へと翻訳される。ところで、遺伝暗号って何でしょう?翻訳されるなら、その通訳はだれでしょう?ここでは、遺伝暗号の分子機構を解説しましょう。
遺伝暗号とコドン
翻訳では、mRNA中の塩基配列情報がタンパク質のアミノ酸配列情報へと変換される。塩基配列は、アデニン(A)・グアニン(G)・シトシン(C)・ウラシル(U)の4種類の塩基で構成される。一方のアミノ酸配列は、20種類のアミノ酸で構成される。したがって、翻訳で塩基とアミノ酸とを1:1で対応させることはできない。2つの塩基の組み合せを使っても、16通りの情報しか作れないため、20種類のアミノ酸を指定するには不十分である。そこで遺伝暗号では、連続したコドンとよばれる3つの塩基の組み合せで1つのアミノ酸を指定する。
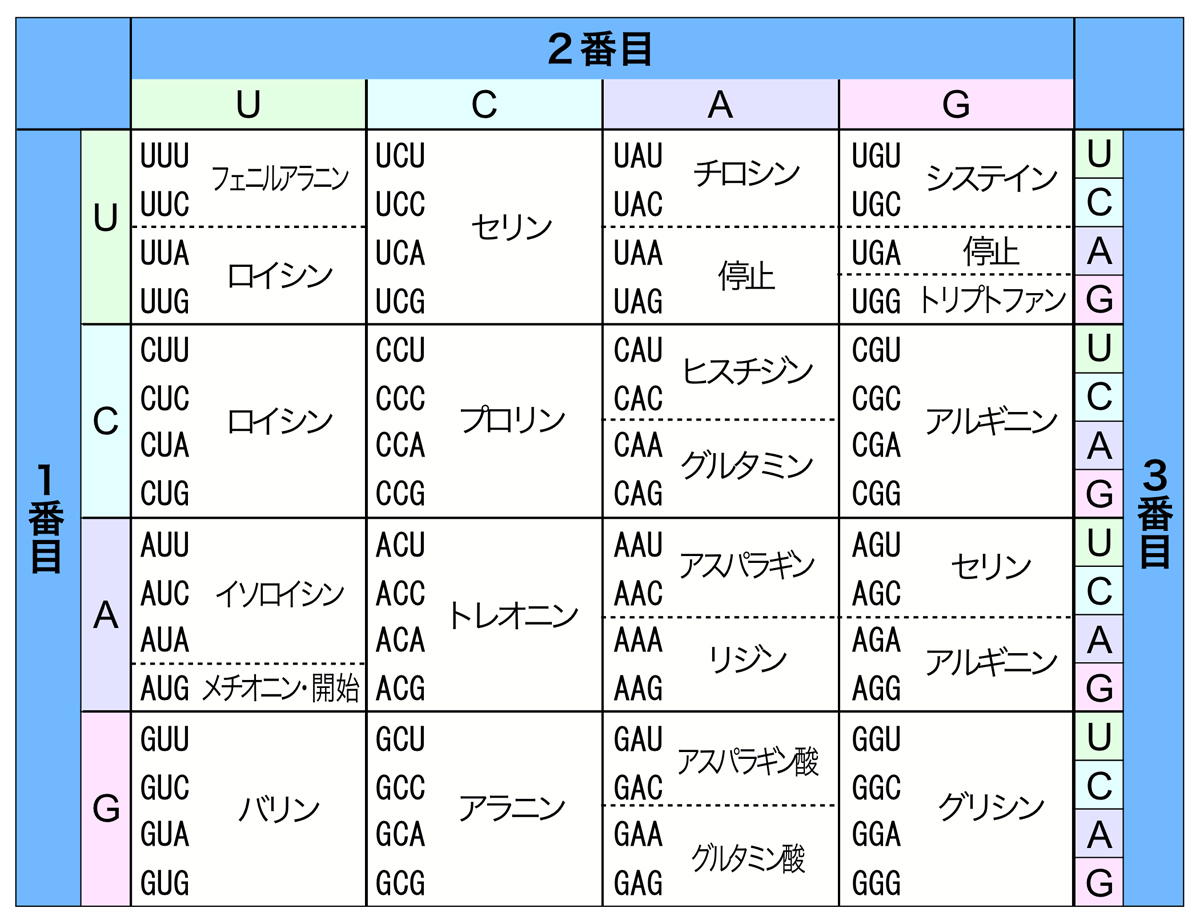
上の表はいわゆるコドン表であり、どのコドンがどのアミノ酸を指定するかがまとめられている。原理的に64通りのコドンがあり、各コドンが1つのアミノ酸を指定する。AUGコドンはアミノ酸であるメチオニンを指定するだけでなく、翻訳の開始シグナルとしても機能する。また、UAA, UAG, UGAの3つのコドンは、翻訳の停止を指令するシグナルとなる。
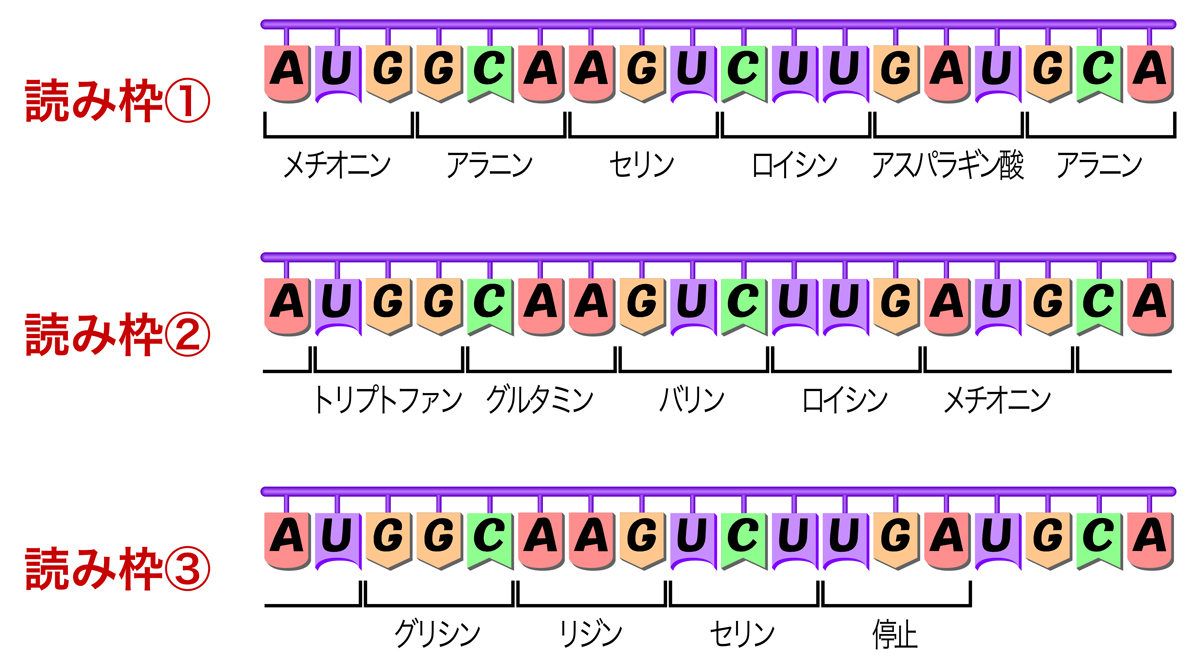
遺伝暗号を読んでいく上で重要なことは、mRNAを5’→3’方向に読んでいくこと、重複なく連続的に読むことである。そうすると、mRNA上には3つの可能な読み枠があることになる。つまり、どの塩基から読み始めるかで、3通りの異なるアミノ酸配列を指定できる。どの読み枠が正しいかは、特定のシグナルにより決定されるが、それは実際の翻訳の頁で説明しよう。
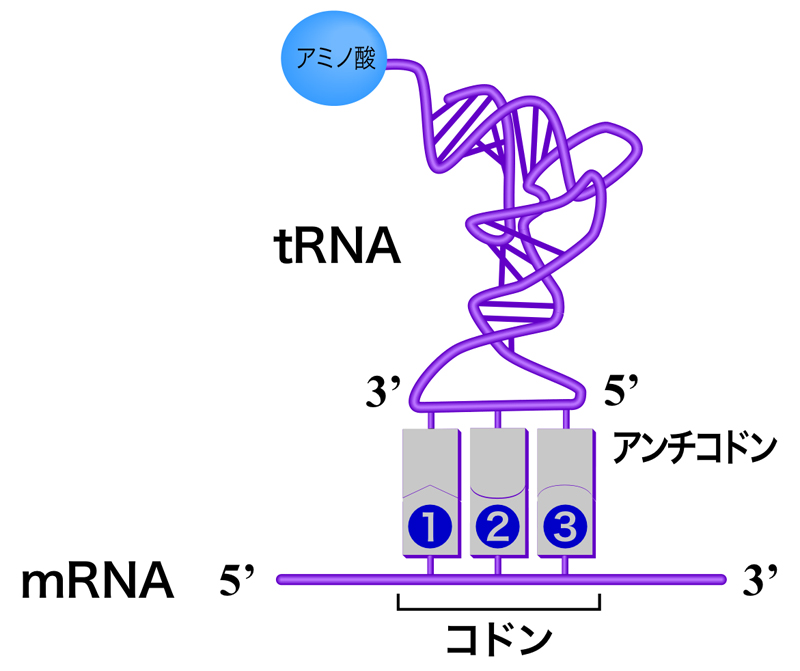
tRNA分子
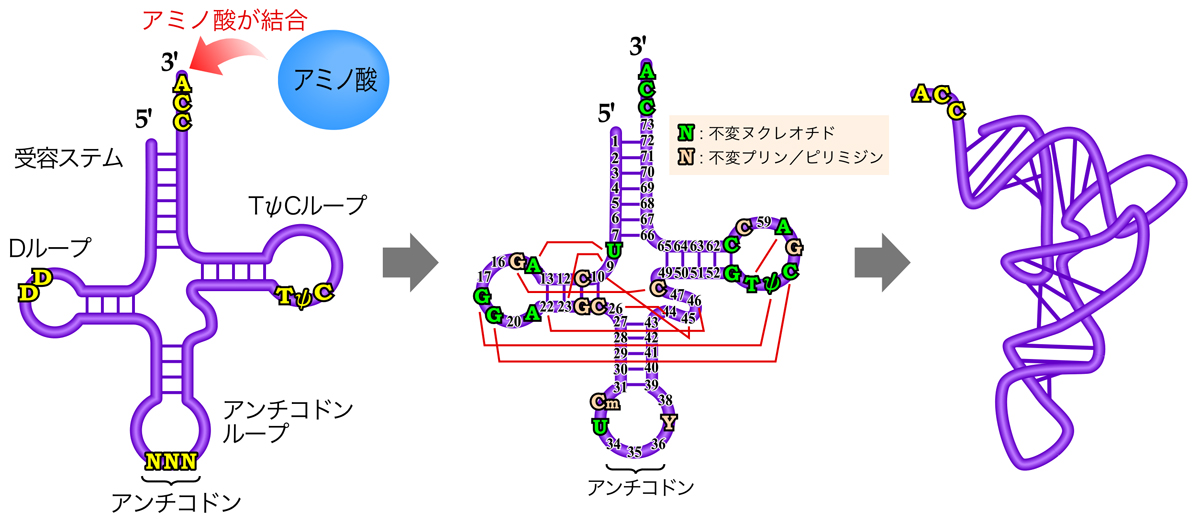
翻訳における通訳の役割を果たすのが、運搬RNA(tRNA)分子である。tRNAは約80ヌクレオチドの短いRNA分子であり、分子内塩基対により下図のようなクローバー型構造を形成する。これにより、以下の4つの領域が形成される。
- CAA配列をもち、コドンに適合するアミノ酸が結合する受容ステム
- ジヒドロウリジン(D)を含むDループ
- TψC配列を含むTψCループ(Tループ)
- コドンと相補的なアンチコドンを含むアンチコドンループ
つまり、mRNAのコドンと相補的なアンチコドンと、コドンに適合するアミノ酸を両方もつことにより、tRNAは通訳としての機能を果たすのである。
このようなtRNAの構造は、原核生物と真核生物とで共通である。しかし、原核生物ではCCA配列が遺伝子中にすでにコードされているのに対し、真核生物ではtRNAの転写後に付加される。
また、クローバー型の二次構造をもつtRNAは、さらに上図真ん中に赤線で示された塩基間の水素結合によりDループとTψCを合わせるように折りたたまれ、右のようなL字型の立体構造を形成する。

tRNAの特徴として、約10%のヌクレオチドで修飾塩基が使われる。最大で25%のヌクレオチドが修飾されるものもあるらしい。上の図は、tRNAで使われる修飾塩基の例を示している。例えば、イノシンはアデニンの修飾により形成されるが、これは後述するようにアンチコドンの塩基対形成に重要である。また、tRNAでもよく使われるメチル化修飾は、不適切な水素結合(塩基対)の形成を阻害し、これによって不適切な構造の形成を阻害するといわれる。その他、修飾塩基はL字型の立体構造の形成を助けたり、正しいアミノ酸を付加するための認識に重要であったりする。
遺伝暗号の縮重
64通りのコドンは、20種類のアミノ酸をコードするには多すぎる。そこで、コドン表を見ても明らかなように、1種類のアミノ酸を指令するのに複数のコドンが使われている。しかも、コドンの1番目と2番目の塩基は共通で、3番目の塩基だけが異なるコドンが使われる。これを、遺伝暗号の縮重という。遺伝暗号の縮重は、以下の2つの仕組みで成り立っている。
- 1個のアミノ酸に対応するtRNA分子を2種類以上もつ
- 2種類以上のコドンと対合できるtRNA分子がある
下の表は、ヒトゲノム中に含まれるtRNA遺伝子をまとめたものである。左から、アミノ酸・対応するコドンと相補的なアンチコドンの塩基配列・そのアンチコドンをもつtRNA遺伝子の数を示している。
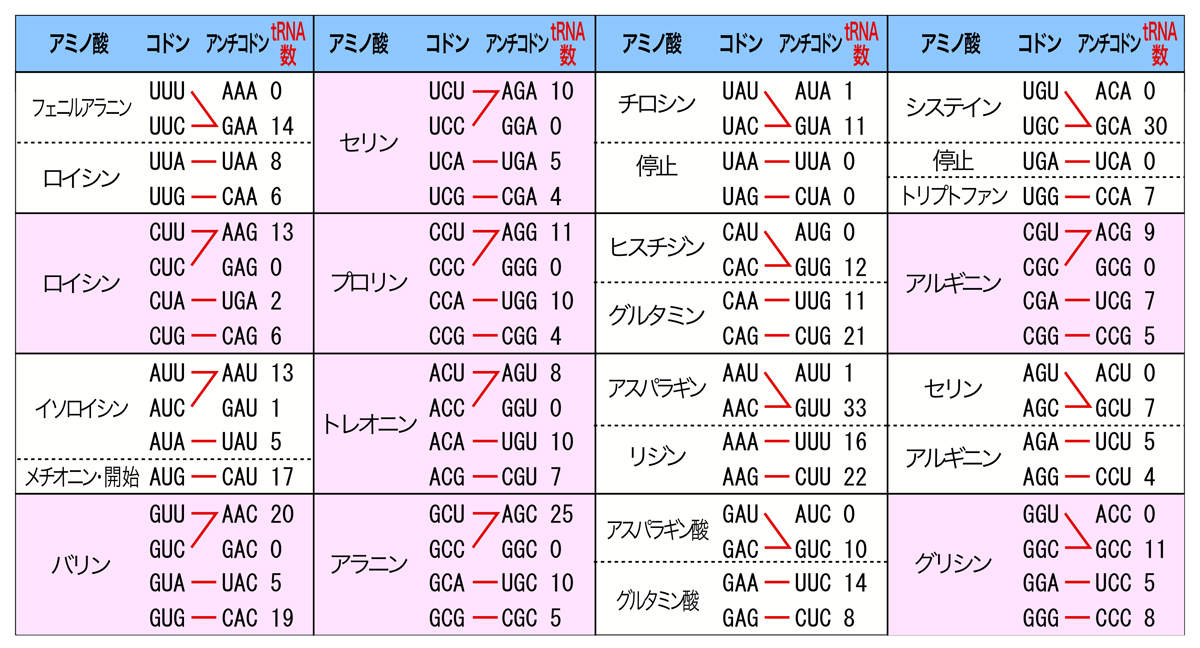
一番左下バリンを例に説明すると、バリンを指令する4つのコドンのうち、GUAとGUGにはそれぞれ相補的なアンチコドンをもつtRNA遺伝子が存在する。つまり、「1個のアミノ酸に対応するtRNA分子を2種類以上もつ」のである。一方、GUUとGUCに対しては、AACアンチコドンをもつtRNAのみが存在する。AACアンチコドンの1番目のAは修飾されてイノシン ( I )となり、コドンの3番目のウラシル (U)とシトシン (C)の両方に対応できるのである。つまり、「2種類以上のコドンと対合できるtRNA分子がある」のである。
真核生物で保存されたパターンとして、4つのコドンで1つのアミノ酸をコードする4-コドンボックスでは、コドンの3番目の塩基(ゆらぎの位置)のウラシル (U)とシトシン (C)に対して、アデニン (A)の修飾によるイノシン ( I )を使う。一方2つのコドンで1つのアミノ酸をコードする2-コドンボックスでは、ゆらぎの位置のウラシル (U)とシトシン (C)に対して、グアニン (G)を使うようである。グリシンは例外であり、またこのパターンから外れるtRNAも3種類あるようである。

こうしてヒトでは、20種類のアミノ酸に対して48種類のアンチコドンをもつtRNAで対応している。一方細菌では、イノシン ( I )がウラシル (U)とシトシン (C)とアデニン (A)の3つの塩基と変則的に塩基対を形成することにより、31種類のアンチコドンをもつtRNAで20種類のアミノ酸に対応している。
アミノアシルtRNA合成酵素
tRNAの3’末端にアミノ酸が結合したものを、アミノアシルtRNAという。それに対して、tRNAの3’末端にポリペプチドが結合したものを、ペプチジルtRNAという。このペプチジルtRNAは、翻訳の中間産物として次の頁で出てくるので、覚えておきましょう。
アミノ酸を対応するtRNAに共有結合させてアミノアシルtRNAを合成するのが、アミノアシルtRNA合成酵素であり、aaRSと略記される。aaの部分にはアミノ酸の3文字表記が入り、20種類のアミノ酸に対応する20種類のアミノアシルtRNA合成酵素があることになる。それぞれのアミノアシルtRNA合成酵素は、1つのアミノ酸とそれに対応する1セットのtRNAを認識する。
アミノアシルtRNA合成酵素によるtRNAへのアミノ酸の付加は、2段階の反応で行われる。まず第一段階として、アミノ酸のカルボキシル基(COOH基)がアデノシン一リン酸(AMP)と結合して活性化し、アミノアシルAMPとなる。続いて第二段階として、AMPに結合したCOOH基がtRNAの3’末端のOH基に転移して、アミノアシルtRNAとなる。

アミノアシルtRNA合成酵素がtRNAに適切なアミノ酸を付加することが、正確な翻訳には重要な要素となる。実は、アミノアシルtRNA合成酵素には、DNAポリメラーゼのような編集機能がある。アミノアシルtRNA合成酵素の触媒部位では、適切なアミノ酸が最も親和性が高くなっており、そのためtRNAに正しいアミノ酸が付加される。しかし、イソロイシンとバリンのように似た構造のアミノ酸では、頻繁にイソロイシンを認識する酵素がバリンを誤って認識してしまう。もし誤ったアミノ酸が付加された場合、そのアミノ酸は編集部位へと送られる。編集部位では、正しいアミノ酸はくぼみに入らないが、よく似た誤ったアミノ酸はくぼみに入るため、誤ったアミノ酸は加水分解により除去される。このような編集機能により、誤りの頻度は4万回に1回程度となっている。

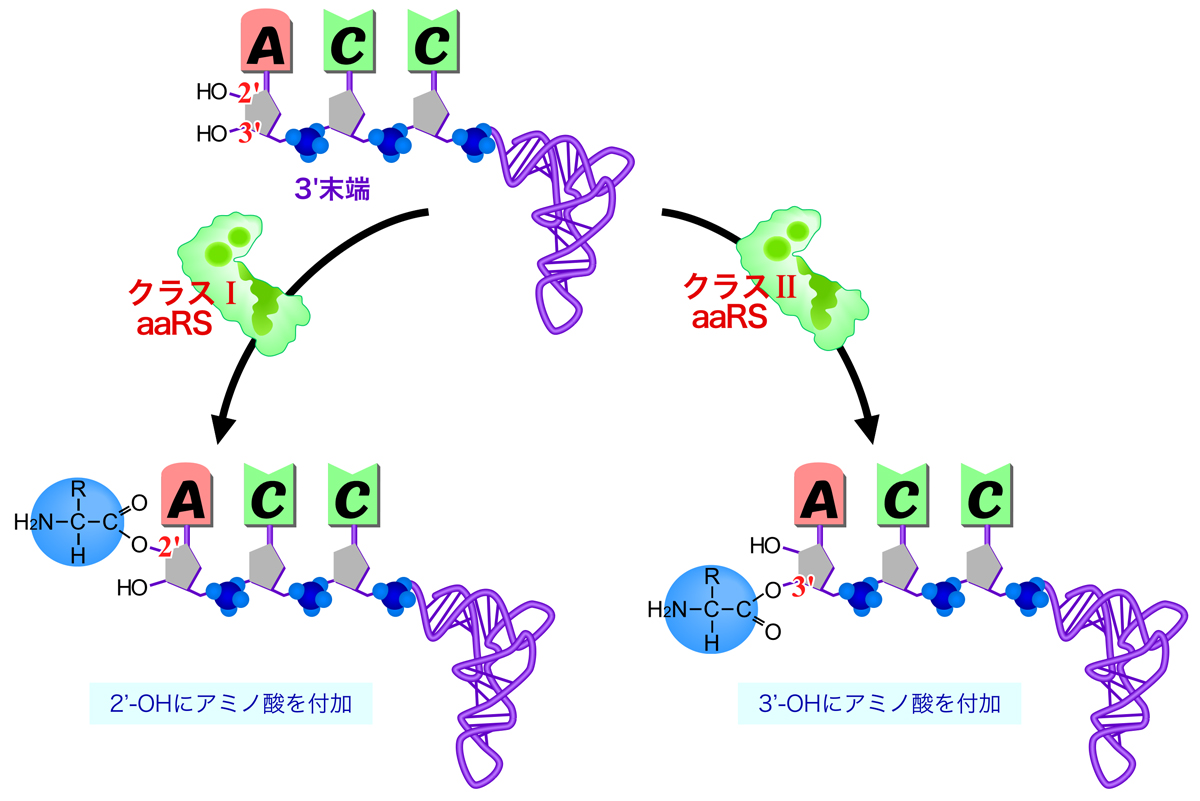
上述のように、20種類のアミノ酸ごとに異なるアミノアシルtRNA合成酵素が存在する。アミノアシルtRNA合成酵素は、ATP結合モチーフの違いにより2つのクラスに分類される。クラスⅠは、多くが単量体の酵素であり、3種類の酵素は二量体である。一方クラスⅡは、多くが二量体の酵素であり、四量体のものもある。

さらに、アミノアシルtRNA合成酵素のクラスにより、アミノ酸が付加されるtRNAの部位が異なる。tRNAの3’末端には、2’-OHと3’-OHの2箇所のOH基がある。クラスIの酵素はすべて2’-OHをアミノアシル化するのに対し、クラスⅡの酵素はPheRS以外は3’-OHをアミノアシル化する。